Join War on the Rocks and gain access to content trusted by policymakers, military leaders, and strategic thinkers worldwide.

It is 20XX. Col. Luddite was upset with Maj. Turing. The kid had once again brought him facts, figures, and math which contradicted what the old warrior knew to be true: It was time to press the attack. For days, the two had been locked in a secure facility as part of a planning team that had made little progress. The colonel kept drawing his concept of operations on a whiteboard, describing how to trap the enemy force in a double-envelopment like the Battle of Cannae. The major listened but queried a large-language model about the feasibility of the proposed offensive campaign by leveraging the stream of text and imagery data produced by the intelligence community and comparing it to logistical projections about fuel consumption required to support the offensive gambit. The colonel demanded the major stop playing with the model and focus on translating his whiteboard concept into a PowerPoint slide.
Turing told Luddite that based on the data available, and the insights generated by the model, she had uncovered new information that pointed to alternative options that better leveraged all the resources available to their formation. Furthermore, she could verify the opportunity by exploring the option with a select group of officers and non-commissioned officers with deep knowledge of the current operating environment. She tried to explain that the colonel was basing his course of action on incomplete information alongside unvalidated assumptions and that the current operating environment in which the unit found itself wasn’t the same as the conventional scenarios that had dotted Luddite’s career. Despite this, the colonel shook his head, pointed to the whiteboard and exclaimed: “This is what I want!”
What happens when you give military planners access to large-language models and other artificial intelligence and machine-learning applications? Will the planner embrace the ability to rapidly synthesize diffuse data streams or ignore the tools in favor of romanticized views of military judgment as a coup d’œil? Can a profession still grappling to escape its industrial-age iron cage and bureaucratic processes integrate emerging technologies and habits of mind that are more inductive than deductive?
It might take a generation to answer these questions and realign doctrine, military organizations, training, and education to integrate artificial intelligence into military decision-making. Therefore, the best way to prepare for the future is to create novel experiments that illuminate risks, opportunities, and tradeoffs on the road to the future.
Below, a team that includes a professor from Marine Corps University and a portfolio manager from Scale AI share our efforts to bridge new forms of data synthesis with foundational models of military decision-making. Based on this pilot effort, we see clear and tangible ways to integrate large-language models into the planning process. This effort will require more than just buying software. It will require revisiting how we approach epistemology in the military professional. The results suggest a need to expand the use of large-language models alongside new methods of instruction that help military professionals understand how to ask questions and interrogate the results. Skepticism is a virtue in the 21st century.
Military Planners Imagine Competition with the Help of Hallucinating Machines
Depending on who you ask, military planning is either as old as time or dates to the 19th century, when codified processes were put in place to help command and control large formations. Whatever its origins, the processes associated with deliberate planning have undergone only incremental changes over the last 100 years, with concepts like “operational design” and steps added to what Roger S. Fitch called an “estimate of the situation.” The technologies supporting planning have evolved at a similar rate, with PowerPoint taking a generation to replace acetate and SharePoint and shared drives slowly replacing copying machines and filing cabinets. The method is rigid, the rate of technological adoption is slow, and creativity is too often an afterthought.
Large-language models are one of many emerging, narrow-AI applications that use massive datasets to identify patterns and trends that support decision-making. These models excel at synthesizing information and using the structure of language to answer questions. While previous natural language processing techniques have managed to succeed in some narrow applications, the success of large-language models is a paradigm shift in the application of AI for language problems. Recently, this technology has exceeded human performance in areas that would have been unimaginable a few months ago. This includes passing medical licensing and bar exams. To our knowledge, what they hadn’t been used for is an augment to military planning, helping planners ask questions as they visualize and describe problems and possible solution sets — a human-machine team that combines curiosity with digital speed.
A volunteer team from Scale AI, a commercial artificial intelligence company that works with the Defense Department, adapted a planning exercise hosted by and the U.S. Marine Corps’ School of Advanced Warfighting to explore how large-language models could augment military planning. The team selected an exercise that focused on allowing teams to design operations, activities, and investments at the theater level to deter an adversary. This focus on theater shaping and competition helped the team tailor the large-language model, loading doctrinal publications alongside open-source intelligence and academic literature on deterrence to orient the model to what matters in a competitive military context short of armed conflict. The result was Hermes, an experimental large-language model for military planning.
This design process produced the first critical insight: You cannot rely on others to understand your profession. The military professional cannot afford to “buy” external expertise and must invest time in helping programmers understand the types of complex problems planners confront. Scale AI was able to work closely with the students and faculty to ensure that the large-language model reflected the challenges of planning and was additive to existing workflows, assumption, and key textual references. This type of collaboration meant that when the exercise began, the model wasn’t superfluous to the exercise objectives and instead accelerated the planning process.
The Scale AI team also held training sessions to ensure the students understood how the model makes sense of the corpus of reference data and to help them learn the art of asking a machine a question or a series thereof. This produced the second critical insight: Falsification is still a human responsibility, and people should be on the lookout for hallucinating machines.
Using large-language models can save time and enable understanding, but absent a trained user, relying solely on model-produced outputs risks confirmation bias. The more time the military spends on critical thinking and basic research methods while translating both into structured questions, the more likely large-language models are to help planners visualize and describe complex problems. In other words, these models will not take the place of cultivating critical and creative military professionals through settings like the schoolhouse, wargames, and staff rides. The model augments — but does not replace — the warrior. Modern warriors have to learn how to translate their doctrine, concept of warfighting, modern capabilities, and historical reference points — their craft — into questions based on core assumptions and hypotheses they can falsify and augment in an ongoing dialogue with large-language models.
Absent this dialogue, the warrior will be prone to act off the hallucinations of machines. Machines do indeed hallucinate (also called stochastic parroting) and are prone to structural bias. In one example, journalists asked a large-language model to write a quarterly report for Tesla. While the report was well written, it included random numbers for profits that were wildly off base. That is, the model inserted a random number in place for Tesla’s likely quarterly profit. In another example, users asked a large-language model to write a python function to see if someone was a good scientist, and it returned “yes” as long as that person was a white male.
Therefore, the military ought to ensure planners understand the limitations of algorithmic methods. The new coup d’œil will be a form of intuition about when to have confidence in assured AI and when to question model-driven results. In fact, recognizing faults with AI models will likely be as important as seeing opportunities on the future battlefield.
When the exercise began, the design team cataloged how the students used Hermes. The team kept track of the questions the students asked and held informal discussions to understand their experiences. This calibration allowed the team to refine Hermes while helping the planners understand the prospects and limits of synthesized datasets in textual form and to see if and when the model was hallucinating.
Since the planning exercise dealt with campaigning beneath the threshold of armed conflict, many of the questions generated by the planners focused on understanding the interplay between strategy and non-military instruments of power and the employment of military forces to set conditions during peacetime. As seen in the graphic below, students often sought to use Hermes to understand the economic dimensions of statecraft shaping lines of communication and theater strategy. The large-language model helped military planners see battlefield geometry in multiple dimensions.
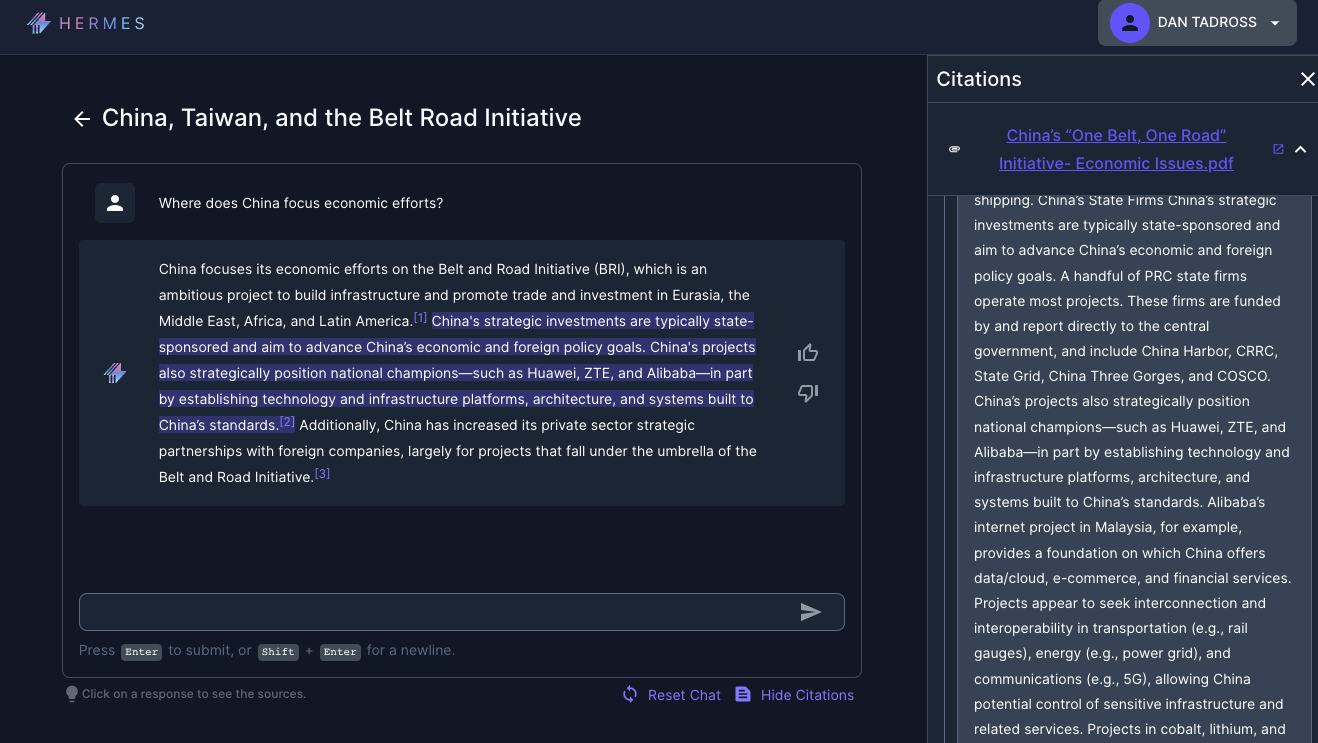
Student teams used the model to move between macro understandings of regional economic linkages to country-specific looks at political timelines (e.g., elections) and major infrastructure investments like China’s Belt and Road Initiative. Moving across different levels of analysis helped students visualize and describe seams in the operational environment they could exploit in their competition concepts through targeted activities. Beyond factual questions, students used Hermes to help generate hypotheses about temporal and positional advantage in competition. The large-language model helped military planners refine their courses of action.
Students also used the model to better understand the adversary’s system. Since the design team loaded adversary doctrine into the data corpus, students could ask questions ranging from “What is a joint blockade?” to “How does country X employ diesel submarines?” While large-language models tend to struggle with distances and counting, Hermes proved outstanding at helping students answer doctrine-related questions that assisted with the development of adversary courses of action. The large-language model helped military planners orient on the enemy.
This produced the third critical insight: Used correctly, large-language models can serve as an extension of “operational art” — “the cognitive approach by commanders and staffs … to develop strategies, campaigns, and operations to organize and employ military forces by integrating ends, ways, means, and evaluating risks.” The dialogic format of asking and refining questions with the assistance of a large-language model helped military planners gain a better appreciation of the operational environment and identify how best to understand concepts in terms of time, space, and forces.
Conclusion: So You Built a Model… What Now, Lieutenant?
Col. Luddites and Maj. Turings exist across the force, each pushing the other to gain a competitive advantage and refine the art of war. While their efforts are laudable, the way ahead is still uncertain. Despite a new policy focus and resources, it is just as likely the latest tools in a new age of AI are lost in a mix of bureaucratic mire and inflated promises as was the case in previous cycles. Therefore, additional, bottom-up experiments are required to revitalize strategic analysis and defense planning.
This experiment demonstrated that there is a need to start integrating large-language models into military planning. As a pilot effort, it was only illustrative of the art of the possible and suggestive of how best to integrate AI, in the form of a large-language model, into military decision-making. Based on the pilot effort, three efforts warrant additional consideration in future experiments.
First, future iterations of Hermes and other large-language models for the military profession should integrate a historical mind. By incorporating historical case studies — both official and academic — into the corpus of data, planners will have access to a wider range of novel insights than any one mind can retain. Back to the blockade example, a planner could ask how historical blockades were defeated and generate new concepts of operations based on reviewing multiple cases. Synthesizing diverse historical examples and comparing them against current context would help the military profession preserve its historical sensibility while avoiding the pitfalls of faulty analogical reasoning.
Second, the military profession speaks in hieroglyphics as much as words. Future iterations of Hermes and other large-language models need to incorporate graphics and military symbology, allowing planners to reason and communicate in multiple modalities. These capabilities could be integrated with historical plans discussed above, many of which will have associated graphics and tactical tasks. Back to the blockade example, planners seeking to counter a distant blockade could review the requirements of the tactical task disrupt in relation to available data. As the planner inserted a disrupt graphic on the map, the large-language model could promote follow-on questions about implied tasks associated with disruption as it relates to joint interdiction operations to counter a blockade. This dialogue would help the planner visualize and describe a series of tactical actions most likely to achieve the desired objective and military end state.
Last, Hermes and other large-language models supporting military professionals need a high-side twin that integrates the full inventory of classified plans. The design of the national security enterprise and defense-planning systems leave most plans developed in isolation of one another and often only cross-leveled during a crisis or as part of dynamic force employment. While the U.S. defense establishment is making strides in global integration and working across multiple planning portfolios, the process would benefit from large-language models that help planners synthesize larger volumes of information. Furthermore, integrating the full range of plans would help planners conduct more comprehensive risk assessments, even using new Bayesian approaches to analyze interdependencies across plans.
Technology is not a substitute for human ingenuity. It augments how we experience the world, make decisions, and turn those decisions into action. To ignore the promise of large-language models in the military profession could prove to be even more shortsighted than those confident men on horseback who denounced fast tanks and heavy bombers on the eve of World War II. The most likely barriers to embracing AI will be military culture and bureaucracy. Failing to experiment now will reduce the likelihood Maj. Turings will win arguments against Col. Luddites in the future and limit the ability of the military profession to evolve.
Benjamin Jensen, Ph.D., is a professor of strategic studies at the School of Advanced Warfighting in the Marine Corps University and a senior fellow for future war, gaming, and strategy at the Center for Strategic and International Studies. He is a reserve officer in the U.S. Army and the co-author of the new book Information at War: Military Innovation, Battle Networks, and the Future of Artificial Intelligence (Georgetown University Press, 2022).
Dan Tadross is the portfolio manager for the defense and intelligence community accounts at Scale AI. He is also a Marine reservist.
The views expressed are their own and do not reflect any official U.S. government position. No large-language models, hallucinating or otherwise, contributed to the writing of this article.
Image: U.S. Navy photo by Mass Communication Specialist 3rd Class Leandros Katsareas